

So here we go with a practical attempt article; to try to run a LLM locally. It goes first with a little bit of web research. I have identified plenty of seemingly good articles detailing steps to be able to do so.
There is a variety of good guides really; could not be sure which would be recent enough and give me a good steep learning curve; and, at the end, of course success.
Here is my adventure; I marked one from beebom. "https://beebom.com/how-run-chatgpt-like-language-model-pc-offline/" Needs python and Node.JS which are already straightforward to get installed and running. For my adventure; I am on Windows; seems like similarly easy to get these running on Mac and linux also.
Anyways; after all the requirements installed and folder structure setup; I go with the flow and chose the easiest-guided example and do "npx dalai llama install 7B" and after that "npx dalai serve" which brings me to a web interface running locally on my desktop:
What happens after this; is a little blurry. I replace the prompt line with my question and press go; I get nothing back. Interestingly; I do not see any resource usage happening also.
A few futile attempts and I enable debug output; and voila; I get my first challenge. My error is something like the below:
llama_model_load: invalid model file 'models/7B/ggml-model-q4_0.bin' (bad magic) More research about this problem; of course the how-to article was out-of-date; in the past month llama code had been improved; meaning the model data needs to be converted. Blurry moments; with cloning more repos for the conversion code, adding more and more libs and modules to my python installation, nothing seemed to really work in converting.
We never quit. Eventually, following various helper sites and blogs and bug reports; I finally come across and updated llm model data; downloadable from https://huggingface.co/Sosaka/Alpaca-native-4bit-ggml/blob/main/ggml-alpaca-7b-q4.bin
With this file in the correct /models folder of my dalai installation; now my dalai web server actually works and generates results.
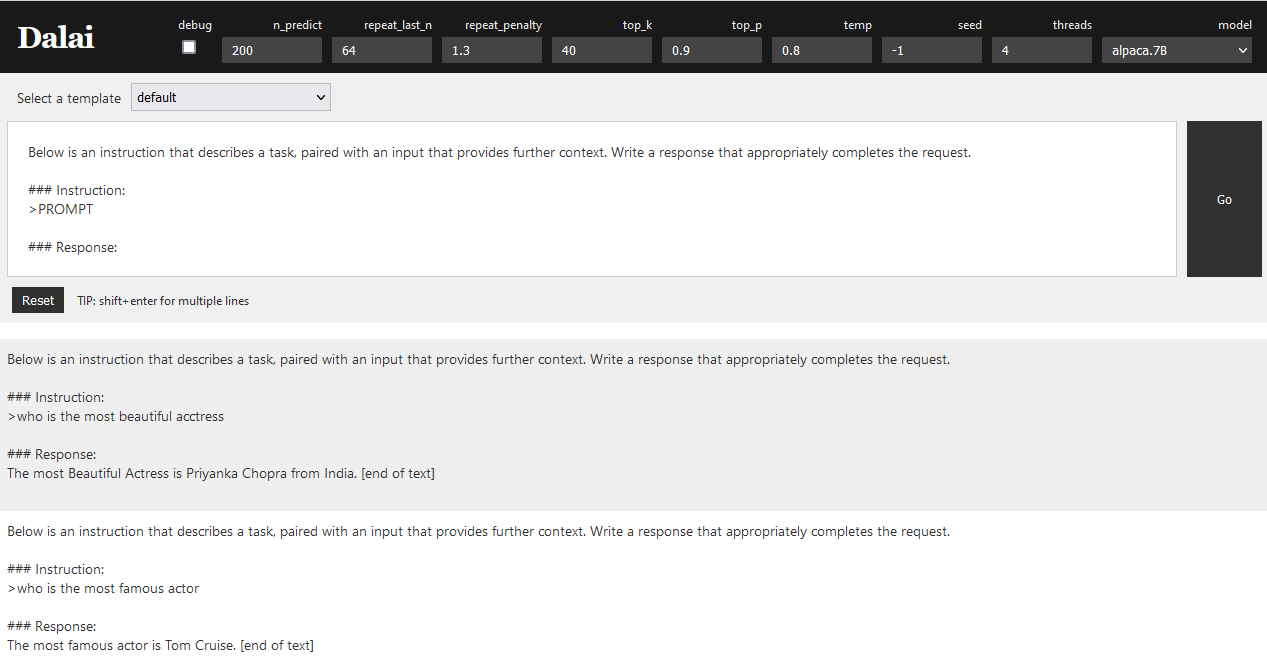
More to learn obviously; the most famous actor being Tom Cruise and the most beautiful actress being Priyanka Chopra.

Anyways; moving on. Plenty of models data to download; place into respective folders and get multiple models run; following the same methodology. The model sizes can go up to hundreds of GB and also the resource consumption and prompt response speed highly varies between models. My desktop rig; that I attempted, this is pretty capable; thou it is not a high price tag server.
More to learn even; I came across these and kept them for further testing; which has proved a fantastic way; not to live through the hassles I summarized above. https://www.infoworld.com/article/3705035/5-easy-ways-to-run-an-llm-locally.html and https://llm.datasette.io/en/stable/
This LLM Python library is a good one; just allows you to use CLI for prompting; with a local or online model of your choice. Depending on the parameters given; downloads the relevant LLM model data (if not yet locally available) and answers. Definitely worth looking at to test various models without any hassle and minus the lost time.
PS C:\users\aloc\dalai\alpaca> llm install llm-gpt4all..
…
PS C:\users\aloc\dalai\alpaca> llm models list
OpenAI Chat: gpt-3.5-turbo (aliases: 3.5, chatgpt)
OpenAI Chat: gpt-3.5-turbo-16k (aliases: chatgpt-16k, 3.5-16k)
OpenAI Chat: gpt-4 (aliases: 4, gpt4)
OpenAI Chat: gpt-4-32k (aliases: 4-32k)
gpt4all: ggml-all-MiniLM-L6-v2-f16 - Bert, 43.41MB download, needs 1GB RAM
gpt4all: orca-mini-3b - Mini Orca (Small), 1.80GB download, needs 4GB RAM
gpt4all: llama-2-7b-chat - Llama-2-7B Chat, 3.53GB download, needs 8GB RAM
gpt4all: orca-mini-7b - Mini Orca, 3.53GB download, needs 8GB RAM
gpt4all: ggml-model-gpt4all-falcon-q4_0 - GPT4All Falcon, 3.78GB download, needs 8GB RAM
gpt4all: ggml-replit-code-v1-3b - Replit, 4.84GB download, needs 4GB RAM
gpt4all: wizardlm-13b-v1 - Wizard v1.1, 6.82GB download, needs 16GB RAM
gpt4all: orca-mini-13b - Mini Orca (Large), 6.82GB download, needs 16GB RAM
gpt4all: starcoderbase-3b-ggml - Starcoder (Small), 6.99GB download, needs 8GB RAM
gpt4all: GPT4All-13B-snoozy - Snoozy, 7.58GB download, needs 16GB RAM
gpt4all: nous-hermes-13b - Hermes, 7.58GB download, needs 16GB RAM
gpt4all: wizardLM-13B-Uncensored - Wizard Uncensored, 7.58GB download, needs 16GB RAM
gpt4all: starcoderbase-7b-ggml - Starcoder, 16.63GB download, needs 16GB RAMI can even run the falcon model and ask questions; and yes I get funny results for the most handsome/beautiful actor/actress.
PS C:\Windows\system32> llm -m ggml-model-gpt4all-falcon-q4_0 "who is the most handsome actor"
100%|██████████| 4.06G/4.06G [00:50<00:00, 80.6MiB/s] Johnny Depp PS C:\Windows\system32> llm -m ggml-model-gpt4all-falcon-q4_0 "who is the most handsome actor"
Johnny Depp
PS C:\Windows\system32> llm -m ggml-model-gpt4all-falcon-q4_0 "who is the most handsome acctress"
The most handsome actor is Leonardo DiCaprio.
PS C:\Windows\system32> llm -m ggml-model-gpt4all-falcon-q4_0 "who is the most beautiful acctress"
The most beautiful actress is subjective and varies from person to person. It's difficult to determine who the most beautiful actress is without further context or information.It is a lot of fun to experiment with these models; and my next attempt will be around understanding how one can train them with local data. Your may review why we dwell on running an LLM locally here:
Leave a Reply